Onion Routing Explained
Onion routing was initially developed in the mid-1990s at the US Naval Research Laboratory and further developed by the Defense Advanced Research Projects Agency (DARPA). This technique was patented by the Navy in 1998, the patent document providing interesting background information to the original concept.
Onion routing is the term used to describe a method of applying anonymity to network messages by wrapping each message in distinct layers of protection to hide the routing of the messages between a client device and a destination device. The messages are encapsulated in layers of encryption analogous to the layers of an onion, hence its name.
Contents
- Why was Onion Routing Developed?
- Anonymizing Proxies
- Mix Networks
- Onion Routing
- Network Chains
- Building the Chain
- Authenticating the Connections
- Encrypting Messages
- Cryptographic Overheads
- Weaknesses
- Poisoned Nodes
- Timing analysis techniques
- Exit Server vulnerability
- Destination Device Restrictions
- Summary
- Resources
Why was Onion Routing Developed?
Traditional VPN and proxy networks implement anonymity by disguising the client device’s IP address so that anyone monitoring the network cannot see where a message has originated from. In most normal circumstances, this provides an adequate level of anonymity for users seeking to protect their privacy as they browse websites and access services over the internet. However, these protection methods do not guarantee anonymity, particularly from sophisticated entities with the resources to conduct network traffic analysis techniques. By looking at the time and size of the data packets leaving the client device and comparing these with data packets traveling across a network, modern computing facilities are able to identify matches and deduce which websites and services a user is accessing, even though the data packets contain no identifiable information for that user.
Such traffic analysis techniques require access to significant processing power and storage capacity. Traditionally only available to government organizations, such resources are now available to commercial organizations and well-funded individuals. There are many reasons why someone using a network may seek complete anonymity.
- Individuals seeking specific healthcare advice
- Corporations cooperating on a market-sensitive business venture
- Journalists communicating with sources
- Whistleblowers contacting regulatory authorities
- Government agencies looking to hide procurement patterns
Communications must be resistant to traffic analysis techniques to be genuinely anonymous to such sophisticated monitoring. Encryption alone does not hide routing patterns between the client device and the destination device and doesn’t offer robust privacy. This is particularly important to government bodies and the intelligence community. Meaningful and sensitive information can be deduced simply by knowing who is talking to whom, even if the conversation’s content remains hidden. This led to the US Navy developing Onion Routing as a solution that was driven by a need to create a traffic analysis resistant communications method that, as a byproduct, offered an answer for other anonymity needs.
The more traffic that exists on any network, the harder it becomes to conduct traffic analysis. Opening up Onion Routing to a broader audience offered benefits to the solution’s developers in obfuscating traffic. As a result, the Naval Research Laboratory released the implementation code under a free license.
It is important to note that onion routing provides anonymous routing, not anonymity. The device receiving data will be able to identify which client device sent that data unless that client device has undertaken an additional step to anonymize the transmitted information. Onion routing is designed to prevent eavesdroppers from identifying where messages from a client device are being sent. Its main goal was to avoid eavesdroppers gleaning intelligence from knowing how much traffic was passing between organizations and looking for patterns or unusual behavior to deduce potential future events.
Anonymizing Proxies
A straightforward method of implementing anonymization is to use a proxy server that takes traffic from client devices and alters the message packets so that they appear to all originate from the proxy server. Anyone monitoring network traffic as it leaves the proxy will be unable to identify which message came from which client device. This approach has several significant drawbacks. If the proxy server is compromised, then all communications through the proxy server are compromised. If a denial of service attack is launched on the proxy server, all communications to and from all client devices are disabled. Finally, this approach will not hinder the use of network traffic analysis techniques to match the anonymized messages leaving the server to the messages sent by the client devices.
Mix Networks
One alternative method of implementing anonymization is to use a mix network. Here proxy servers take traffic from multiple client devices, shuffles the received message packets, and then resends them in a randomized order to make the link between the messages leaving the proxy servers and the messages sent by the client devices harder to establish. A mix network relies on a chain of proxy servers with no knowledge of the path a message packet has taken beyond which proxy it has received the packet from and which proxy it is sending the packet on to. While this approach is more resilient than a simple anonymizing proxy server, it will also not hinder network traffic analysis techniques to match the anonymized messages leaving the mix network to the messages sent by the client devices.
Onion Routing
Onion routing was developed as a means to implement robust anonymization that was immune to network traffic analysis by combining features from anonymizing proxy servers and mix networks. Onion routing relies on a network of relay servers with designated entry servers and exit servers. A client device connects to an entry server, and the message packets travel to the entry server, then onwards through multiple relay servers before reaching an exit server. From the exit server, the anonymized message packets are then routed to the destination device. The protocols used for transferring data are designed to facilitate a wide range of data types, including web-browsing commands, e-mail messages, remote login commands, and file transfer.
Onion routine relies on layers of encryption, applied as message packets travel between relay servers to effect anonymity. The message protocols use public-key encryption to establish secure and authenticated connections between each device in the network chain and the more efficient symmetric encryption to secure the data passing across the network.
A network chain that employs N relay servers will require the data to be encrypted (N-1) times. As the data is passed to each relay server, that relay server’s layer of encryption is removed to reveal the next relay server’s identity. This ensures that each relay server cannot see the list of relay servers that make up the network chain, only the server’s identity the data was received from and the identity of the server it will be relayed to. Once the data reaches the network chain’s exit server, the final layer of encryption is removed, and the data can be passed to the destination device.
Network Chains
Directory servers maintain a list of all the servers available for the client device to use in building the network chain. These servers are owned and managed by volunteers, and no records are held as to the physical location of servers beyond which geographic region they are located in. This strategy aids in preventing any attacker from gaining physical access to a server.
Building the Chain
The client device follows a four-stage process when employing onion routing to send data across a network.
- The first step is to use the information available on the directory servers to define a route through the relay servers
- The second step is to create an authenticated connection through all the relay servers across the required route
- The third step is to transfer data across the established route
- The fourth and final step is to close the connections leaving no trace of the route used
The following diagram shows a defined route from the client device to the destination device through the available relay servers.
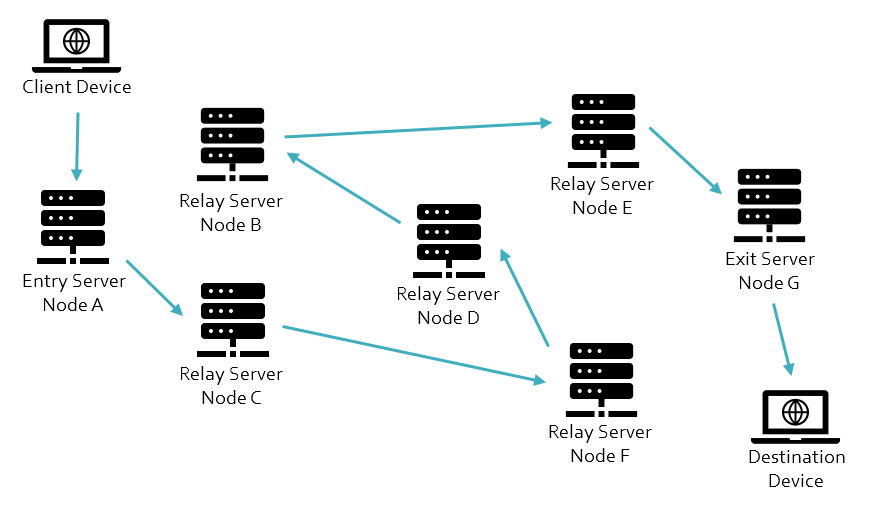
Authenticating the Connections
The client device selects an entry server from the list of available nodes on a directory node to create the authenticated connection. The client device uses asymmetric key cryptography to authenticate its relationship with this ‘Node A’ device, obtaining the directory node’s public key. A secure connection is then created between the client device and ‘Node A’ device using a session key to implement symmetric key cryptography protection for data transferred across this connection.
The client device then uses asymmetric key cryptography to authenticate its connection with the next relay server, in this case, ‘Node C,’ again obtaining the public key from the directory node. A secure connection is then created between the client device and ‘Node C’ device via ‘Node A,’ using a session key to implement symmetric key cryptography protection for data transferred across this connection. It is important to note that ‘Node A’ is not a party to the ‘Node C’ session key and cannot decrypt the data sent to ‘Node C.’
The client device then uses asymmetric key cryptography to authenticate its connection with the next relay server, in this case ‘Node F,’ again obtaining the public key from the directory node. A secure connection is then created between the client device and the ‘Node C’ device via ‘Nodes A’ and ‘C,’ using a session key to implement symmetric key cryptography protection for data transferred across this connection. This process continues until the client device authenticates its relationship with the exit server, in this case, ‘Node G,’ with a secure connection created between the client device and ‘Node G’ device via ‘Nodes A, C, F, D, B, and E.’
Once the connection from the client device to the exit server is established, messages can be passed from the client device to a destination device. The data sent to the entry server is protected with multiple layers of symmetric encryption using the session keys established with each relay server in the reverse order in which they appear in the network chain.
Encrypting Messages
In this example, the data is encrypted using the ‘Node G’ session key, then the ‘Node E’ session key, followed by the ‘Node B’ session key, then the ‘Node D’ session key, then the ‘Node F’ session key, then the ‘Node C’ session key, and finally with the ‘Node A’ session key.
((((((((Data)Node G key)Node E key) Node B key) Node D key) Node F key) Node C key) Node A key)
The encrypted message is passed to the entry server, ‘Node A.’ This server is able to strip away the outer layer of encryption using its session key. This allows ‘Node A’ to identify that the data needs to be routed to ‘Node C.’
(((((((Data) Node G key)Node E key) Node B key) Node D key) Node F key) Node C key)
The message is then passed from the entry server, ‘Node A,’ to the next relay server, ‘Node C.’ This server is able to strip away the next layer of encryption using its session key. This allows ‘Node C’ to identify that the data needs to be routed to ‘Node F.’
((((((Data) Node G key)Node E key) Node B key) Node D key) Node F key)
The message is then passed from the relay server, ‘Node C,’ to the next relay server, ‘Node F.’ This server is able to strip away the next layer of encryption using its session key. This allows ‘Node F’ to identify that the data needs to be routed to ‘Node D.’
(((((Data) Node G key)Node E key) Node B key) Node D key)
The message is then passed from the relay server, ‘Node F,’ to the next relay server, ‘Node D.’ This server is able to strip away the next layer of encryption using its session key. This allows ‘Node D’ to identify that the data needs to be routed to ‘Node B.’
((((Data) Node G key)Node E key) Node B key)
The message is then passed from the relay server, ‘Node D,’ to the next relay server, ‘Node B.’ This server is able to strip away the next layer of encryption using its session key. This allows ‘Node B’ to identify that the data needs to be routed to ‘Node E.’
(((Data) Node G key)Node E key)
The message is then passed from the relay server, ‘Node B,’ to the next relay server, ‘Node E.’ This server is able to strip away the next layer of encryption using its session key. This allows ‘Node E’ to identify that the data needs to be routed to ‘Node G.’
((Data) Node G key)
The message is then passed from the relay server, ‘Node E,’ to the exit server, ‘Node G.’ This server is able to strip away the final layer of encryption using its session key. This allows ‘Node G’ to identify that the data needs to be routed to the destination device.
(Data)
In theory, this process can use as many relay servers as are available to build the network chain, but as this example with just seven servers demonstrates, the encryption overhead of longer chains will impact the network performance.
Cryptographic Overheads
The main disadvantage with onion routing is the processing overhead for the multiple encryption and decryption operations as messages pass across the network. A connection that employs N relay servers will require the data to be encrypted (N-1) times and decrypted (N-1) times. The use of symmetric encryption optimizes latency without compromising security.
However, this does also bring benefits because the encryption performed at each relay server means that the data passing across the network will be different at each network node. This data cannot be tracked by anyone able to monitor the links between each relay server. Also, this process implements link encryption and end-to-end encryption by default.
Weaknesses
Onion routing provides robust anonymity, but it is not infallible. Common vulnerabilities include:
Poisoned Nodes
The simplest method of overcoming the protection that onion routing offers is for a malicious actor to operate entry and exit servers listed in destination nodes as part of the available servers for network chains. This would allow the party operating these poisoned nodes to monitor network traffic for the small percentage of client devices that were unlucky enough to have selected both a poisoned entry server and a poisoned exit server. This technique cannot target specific users but still provides good untargeted intelligence gathering opportunities. There are no current solutions to counter poisoned nodes, but the probability of being unlucky and using compromised entry and exit nodes means the risks are negligible for most users.
Timing analysis techniques
While onion routing obscures the path between a client device and destination device, it does not hide any records of connections between the various devices on a network. Suppose an attacker is able to monitor traffic as it leaves the client devices and arrives at destination devices. In that case, it may still be possible to match traffic from the timing of message packets as they pass over the network. Onion routing makes this task far more complex. The more connections each relay server maintains at any given time, the harder it becomes to collect and process sufficient network traffic to perform traffic analysis. The processing power and storage requirements necessary to achieve such network analysis put this technique beyond all but the best-resourced state-backed attackers.
Compromise of a relay server can aid an attacker in undertaking such monitoring by reducing the traffic volume that requires monitoring. Still, such an attack will only be successful if the attack target happens to use the compromised relay server.
One possible solution is to obfuscate message packages by taking messages from multiple client devices and grouping them together before routing across the network chain. The amalgamated messages cannot be matched back to a message sent by a client device. This has the side effect of improving overall performance by optimizing the overall message traffic’s encryption and decryption processing.
Exit Server vulnerability
A weakness in onion routing is that the exit server has full visibility of the client device’s data sent to the entry server. Suppose this data is not sufficiently protected before it enters the network chain of the onion routing. In that case, a compromised exit server can be used to monitor, or even intercept and change, the data being sent to the destination device. Implementing end-to-end encryption between the client device and the destination device can counter this weakness.
Destination Device Restrictions
It is not uncommon for websites and online services to restrict access to traffic arriving via onion routing. While some websites use Captchas to prevent malicious attackers using onion routing to launch Denial of Service (DoS) attacks, others may block such traffic completely. As a result, onion routing may not be available as an option unless traffic is routed from a known exit server via an intermediatory relay that is not subject to such blocks.
Summary
Onion routing provides a mechanism to improve a client device’s anonymity to a destination device by providing a routing mechanism that makes traffic analysis techniques significantly more challenging to implement. It does not offer anonymous communications but instead allows the identities of parties undertaking communications to be hidden from anyone who is not a party to those communications.
Onion Routing prevents eavesdroppers on a network from identifying which client devices are communicating with which destination devices. It also hides the content of the communications while within the onion routing network chain.
Connection anonymity has practical applications, allowing government agencies to hide who they are in contact with, providing a means for political activists living under repressive regimes to safely communicate, allowing whistleblowers to contact regulatory bodies without fear of repercussions.
The downside of onion routing is the processing requirements can make communications slow, making it impractical for most general internet users with high bandwidth requirements such as gaming, movie streaming, or video conferencing.
Resources
Academic Paper - Onion Routing for Anonymous and Private Internet Connections
Academic Paper - Towards an Analysis of Onion Routing Security
Academic Paper - Anonymous Connections and Onion Routing
Academic Paper - Hiding Routing Information

Stephen is a UK-based freelance technology writer with a background in cybersecurity and risk management.